Encoder-Decoder Architecture
Google Cloud - Generative AI for Developers Learning Path

This is a collection of notes from the Encoder-Decoder Architecture course on Google Cloud taught by Benoit Dherin. Some images are taken from the course itself.
It is a detailed compilation and annotated excerpts will be available on my LinkedIn profile.
Course Overview
Architecture
Training Phase
Serving Phase
What's Next
Architecture
Encoder-Decoder is a sequence-to-sequence architecture i.e. it consumes sequences and spits out sequences.
It performs tasks like Machine Translation, Text Summarization and Question Answering. Another example can be prompts that are given to LLM which result in response from the LLM.
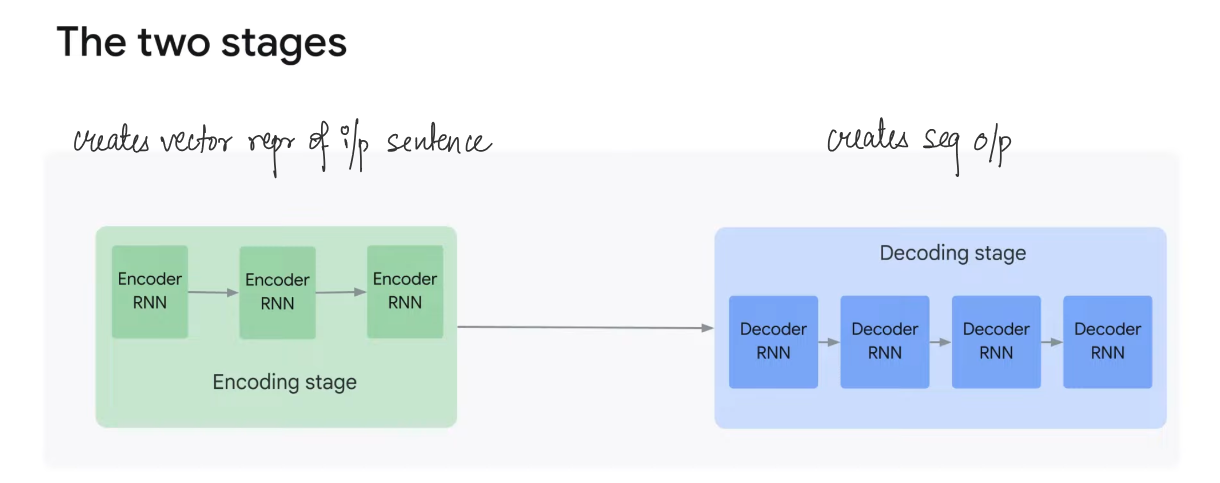
There are two stages: Encoder creates vector representation of input sequence, then Decoder creates sequence output.
Both the Encoder and Decoder can have different internal architecture. These can be Recurrent Neural Networks (RNNs) or Transformer Blocks (in case of LLMs)
Steps
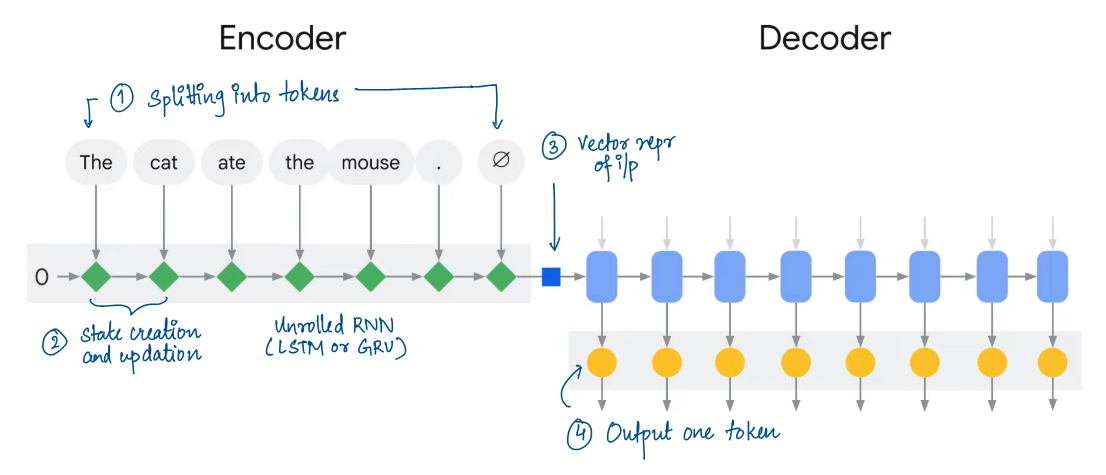
Each input sequence is divided into tokens.
The Encoder takes in one token at a time and produces state representing this token along with all previous tokens.
State is used in next encoding step as input for next token.
After all tokens are encoded, our output is vector representation of input sequence.
The vector representation is then passed to the Decoder.
The Decoder outputs one token at a time using current state and what it has decoded so far.
Training Phase
Dataset is in the form of input-output pairs. Example: Input is sentence in source language and output is sentence in target language.
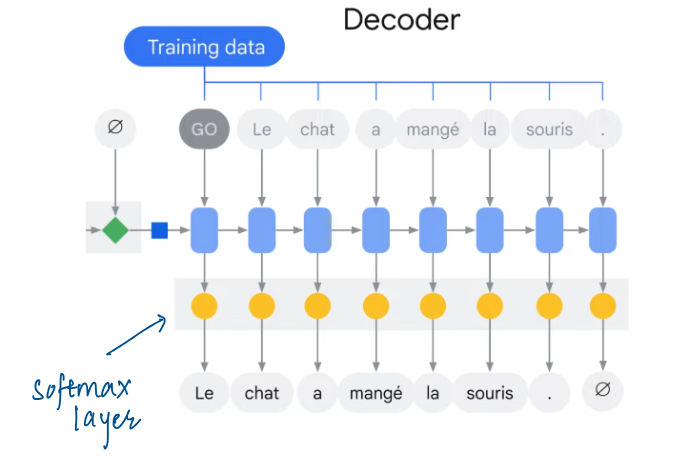
Model corrects weights in training based on error which is the difference between generated output for the input and the true output.
Note:
The Decoder also needs its own input at training time. Hence, we need to provide correct previous token for generating next token.
This process is called Teacher Forcing because it forces Decoder to generate token based on correct previous token and not the token it generated itself.
Teacher Forcing thus needs two input sentences, the original sentence (for Encoder) and left-shifted sentence (for Decoder).Decoder only generates probability of each token in vocabulary. To select appropriate token, we can adopt following strategies:
Greedy Search
This is the simplest strategy. We just choose the token which has the highest probability.Beam Search (BETTER)
We use the probability of generated token to calculate the probability of sentence chunks. Then we keep the chunk with the highest probability.
Serving Phase
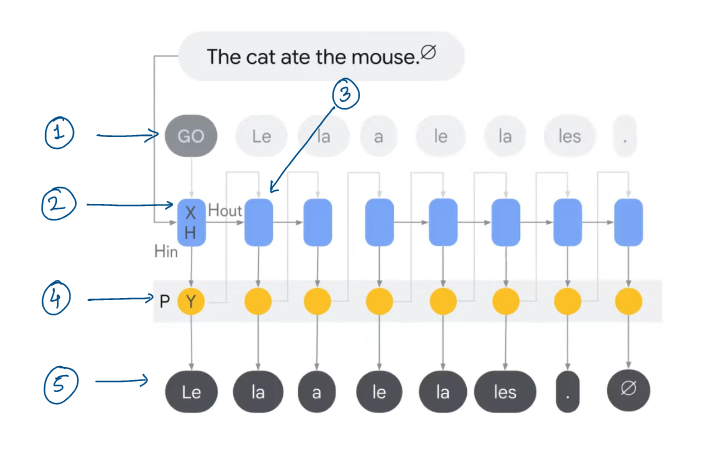
Referring the image above, we perform following steps:
We feed the Encoder representation of the prompt to the Decoder along with special (Start) token that generates the first token.
Start token (GO) is represented using Embedding Layer.
Next, Recurrent layer updates the previous state produced by Encoder into new state.
This new state is passed to Dense SoftMax layer which produces word probabilities.
Finally, we select appropriate word using Greedy Search or chunk using Beam Search.
What's Next?
The internal architectures of Encoder and Decoder model changes performance.
For Google's Attention Mechanism, RNN is replaced by Transformer Blocks.
Ending Note
We learnt about Encoder-Decoder Architecture which is prevalent ML architecture for many sequence-to-sequence tasks.
Next, we will learn about Attention Mechanism that allows neural networks to focus on specific parts of input sequence and improve performance on variety of ML tasks.
Stay tuned for lots of Generative AI content!



