
Introduction to Image Generation
Google Cloud - Generative AI for Developers Learning Path


This is a collection of notes from the Introduction to Image Generation course on Google Cloud taught by Kyle Steckler. Some images are taken from the course itself.
It is a detailed compilation and annotated excerpts will be available on my LinkedIn profile.
Course Overview
Image Generation Families
Diffusion models
Working of Diffusion Models
Recent Advancements
Image Generation Families
Variational Autoencoders (VAEs)
Encode images to a compressed size, then decode back to original size, while learning the data distribution.
Generative Adversarial Models (GANs)
Pit two neural networks against each other. One model (Generator) creates candidates while the second one (Discriminator) predicts if the image is fake or not. Over time Discriminator gets better at recognizing fake images and Generator gets better are creating real images.
Autoregressive Models
Generates images by treating an image as a sequence of pixels. Draws inspiration from how LLMs handle text.
Diffusion Models
Diffusion Models draw inspiration from Physics, especially Thermodynamics. Their usability has seen a massive increase in research space and now commercial spaces too. They underpin many state-of-the-art models that are famous today such as Stable Diffusion.
Types of Diffusion Models

Unconditioned Generation
Models have no additional input or instruction. Can be trained from images of a specific thing for creating images such as human faces or enhancing image resolutions.
Conditioned Generation
These models can generate images using a text prompt or edit the image itself using text.
Working of Diffusion Models
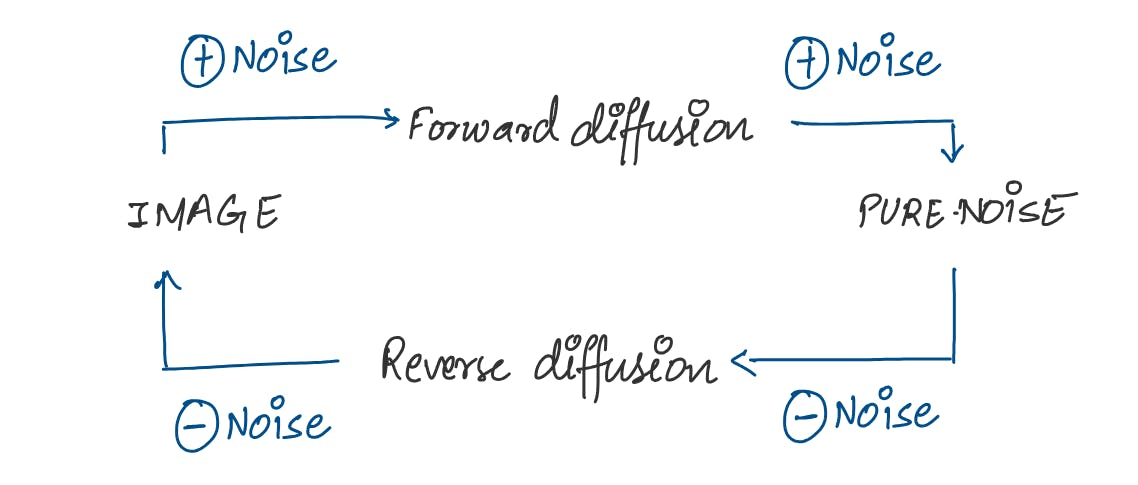
The process consists of two stages:
Forward Diffusion
Systematically and slowly destroy the structure in a data distribution. This is done by adding Gaussian noise iteratively to the existing image.
Reverse Diffusion
Restore structure in data yielding a highly flexible and tractable generative model of data. The model learns how to de-noise an image which can help generate novel images.
Denoising Diffusion Probabilistic Models (DDPM)
The goal is to make a model learn how to de-noise or remove noise from an image.
Then, we can start from pure noise and then iteratively remove noise to synthesize a new image.
Steps:
We start with a large dataset of images.
Forward Diffusion Process
For each image, we add a little bit of Gaussian noise at each timestep.
Iteration through T=1000 timesteps
The above process is repeated for T timesteps, adding more noise iteratively to the image from the last timestep.
End of Forward Diffusion
Ideally, by the end of the forward diffusion process, all structure in the image is gone and we should have pure noise.Reverse Diffusion Process
To go from a noisy image to a less noisy one, we need to learn how to remove the Gaussian noise added at each timestep.
Denoising Model
We train a machine learning model that takes in noisy images as input and predicts the noise that's been added to it.Training Denoising Model
The output of the Denoising model is predicted noise and we know what noise was initially added. We can compare them and thus train the model to minimize the difference between them. Over time the model gets very good at removing noise from images.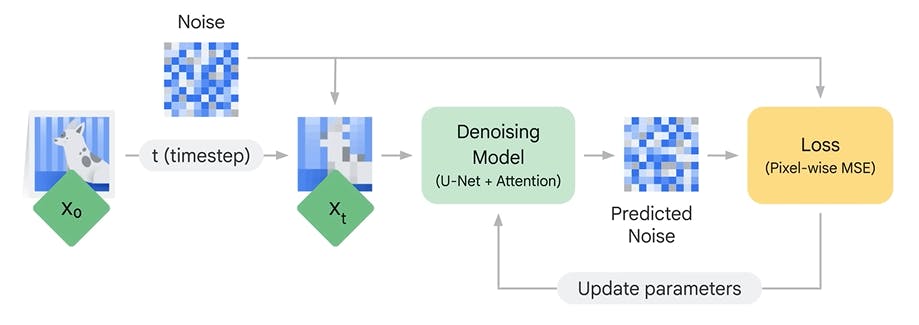
Image Generation
For generating images, we start from pure random noise and pass it through our Denoising model multiple times to generate new images.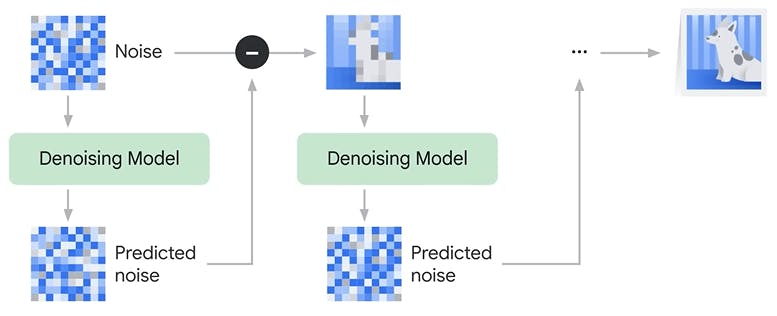
Recent Advancements
Lots of advancements have been made to generate images faster and with more control.
By combining the power of LLMs and Diffusion Models, there has been a huge success in creating context-aware, photorealistic images using text prompts.
Example: Imagen on Vertex AI
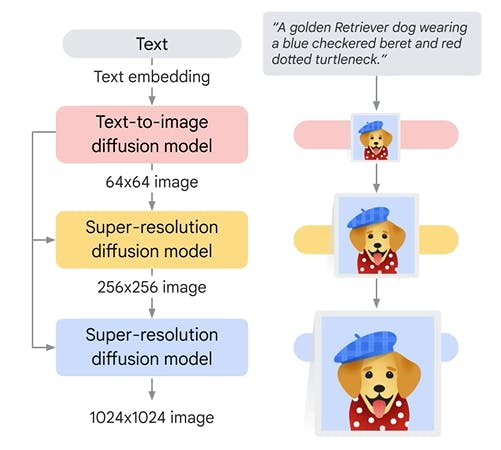
Ending Note
We learned how diffusion models have transformed the image generation space and continue to be at the core of modern image generation models.
Next, we will learn about Encoder-Decoder Architecture which serves as the building blocks of all Transformer Models we use today.
Stay tuned for lots of Generative AI content!