Attention Mechanism
Google Cloud - Generative AI for Developers Learning Path

This is a collection of notes from Attention Mechanism course by Google Cloud, taught by Sanjana Reddy. Some images are taken from the course itself.
It is a detailed compilation and annotated excerpts will be available on my LinkedIn profile.
Note that this article assumes you have basic understanding of how Encoder-Decoder works. For a refresher, check out my Encoder-Decoder Architecture article.
Course Overview
Need for Attention Mechanism
Attention Mechanism
How to Improve Translation
Need for Attention Mechanism
The course explains the need of Attention Mechanism using the example use case of Machine Translation.
For Machine Translation, we can use an Encoder-Decoder model (discussed in previous article) which takes one word at a time and translate them at each time step.
The problem with this approach is that sequence of words doesn't always match between source and target language.
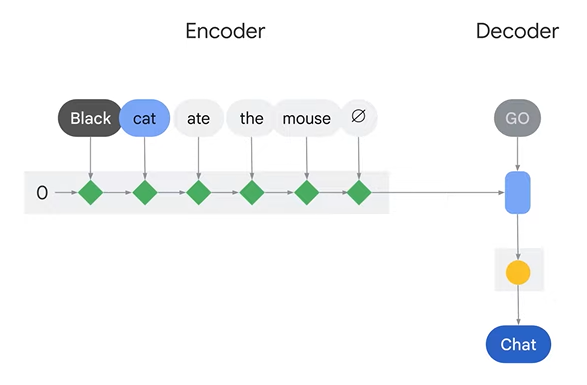
Now, how to train the model to focus more on the word "Cat" than the word "Black" at first time step? This is where Attention Mechanism comes into picture.
Attention Mechanism
Attention Mechanism is a technique that allows a Neural Network to focus on specific parts of input sequence. This is done by assigning different weights to different parts of the sequence with most important parts receiving the highest weights.
Differences from Traditional Encoder-Decoder
Traditional RNN based Encoder-Decoder
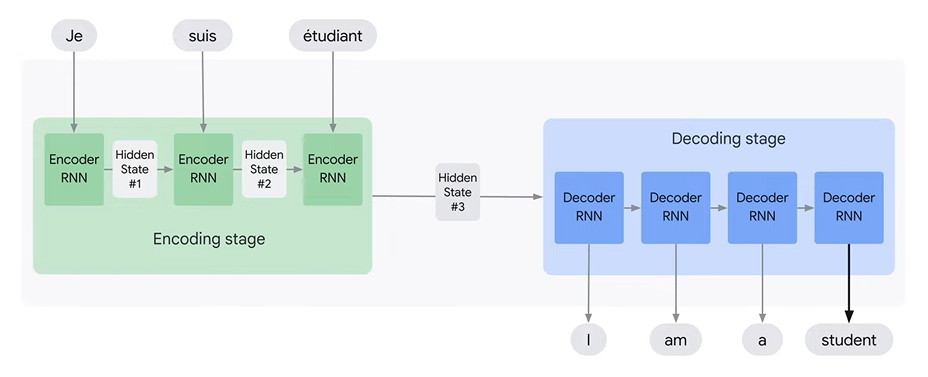
Model takes one word at a time as input, updates hidden state and passes on to next timestep.
In the end, only the final hidden state (Hidden state #3 above) is passed to the decoder.
Decoder works with this state for processing and translates to target language.
Attention Model
Attention Model differs from the traditional model in two major regions:
Passing more data to decoder.
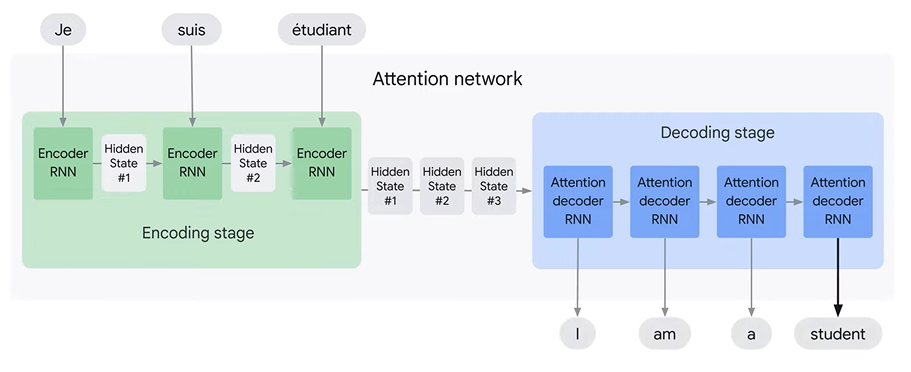
Instead of just passing the final hidden state to decoder, encoder passes all the hidden states from each timestep. This provides more context to decoder.
Extra step before producing output.
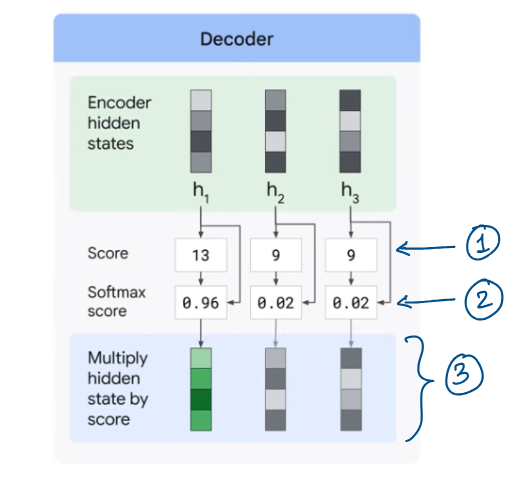
To focus only on more relevant parts, decoder does the following:
Look at set of encoder hidden states that it has received.
Give each hidden state a score.
Multiply each hidden state by its soft-maxed score. This amplifies hidden state with highest score and downsizing states with low score.
How to Improve Translation
Using the differences mentioned above, the course outlines the working of the Attention Network as follows:
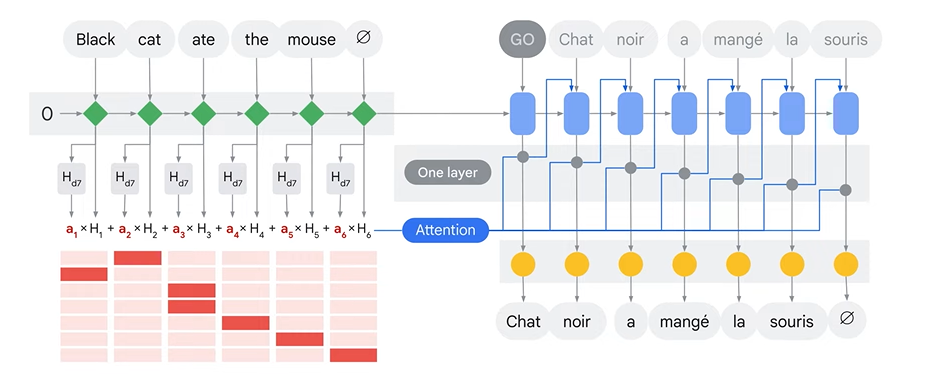
Some notation used above:
"at" represents attention weight at t-timestep.
"Ht" represents hidden state of encoder at t-timestep.
"Hdt" represents hidden state of decoder at t-timestep.
The process during attention step are as follows:
We use the encoder hidden states and Ht vector to calculate context vector at for "t" timestep. This is the weighted sum.
Then concatenate at and Ht into one vector.
Concatenated vector is passed to feedforward neural network, which is trained jointly with the model, to predict next word.
Output of the feedforward NN indicates output word for this timestep.
Process is continued until the End-of-Sentence token is generated by the decoder.
Note:
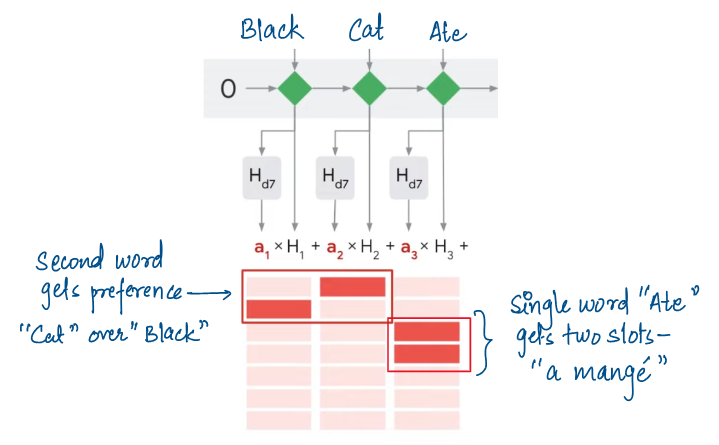
We can see the inversion of words "Cat" and "Black" with attention mechanism. Also, we can see that word "Ate" translates into two words "a mange".
Ending Note
We learnt about how Attention mechanism works and how it improves machine translation task. Next, we will learn about Transformer models and self-attention mechanism and how these are used for text classification, question answering, and natural language inference tasks.
Stay tuned for lots of Generative AI content!



