Easy Perceptron Recipe
Building Perceptron Classifier from Scratch

Introduction
Perceptron is a supervised algorithm, just like K-Nearest Neighbors (KNN) classifier. It is one of the first imitations of our neural system and can be called the Grand-dad of Neural Networks.
The basic structure of Perceptron can be seen in the image below:
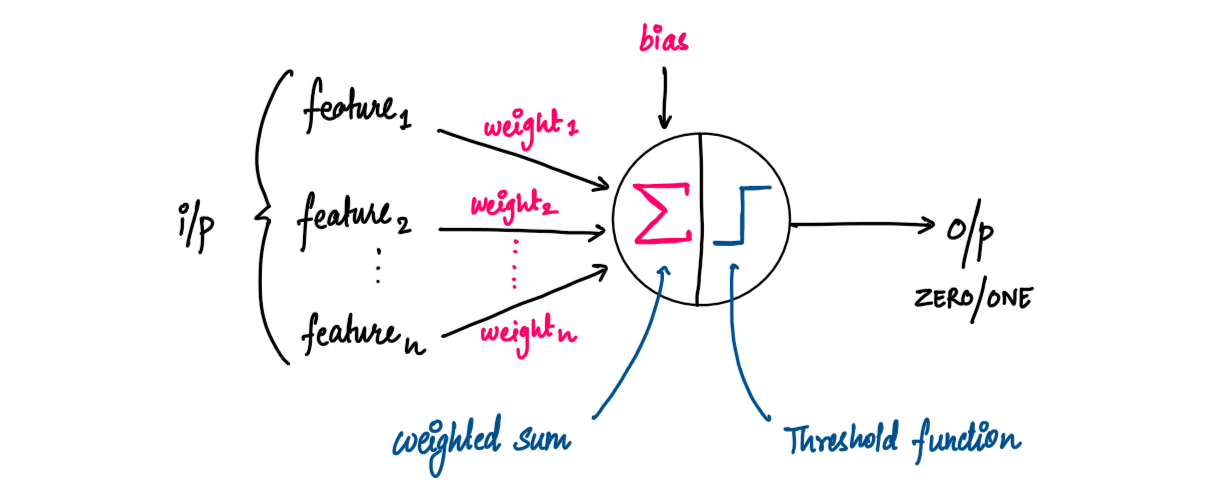
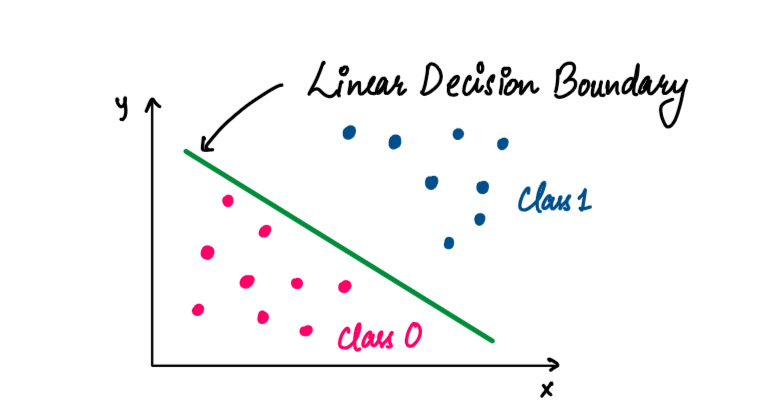
Unlike KNN, which we saw in the previous post, Simple KNN recipe, we don't need to save all the points in the dataset to classify new test points (If you haven't read the KNN recipe, I highly recommend you just skim through it once!). Instead, Perceptron finds out a Linear Decision Boundary that divides our dataset into two classes. So, we only need to remember this boundary for predictions.
Recipe
Now, we define the Perceptron algorithm using an easy cookbook recipe!
If you already know the concepts and want to skip directly to the code, go to the last section titled "Complete Code".
The recipe has the following parts:
Ingredients: We acquire data and preprocess it so that our algorithm can work on it.
Equipment: These are the concepts that help perform classification and are the building blocks of the algorithm.
Directions: Applying the algorithm to the preprocessed data and assessing its performance (comparing our recipe with Master Chef's one! 👨🍳)
Ingredients
We need to create points for two classes which would be then used by our classifier to build a decision boundary. We use the Python library Numpy to create these points as follows:
import numpy as np
from numpy.random import normal
import random
def make_dataset(center1, center2, num_examples):
dataset = list()
# features for Class 0
f1 = normal(loc=center1, size=num_examples)
f2 = normal(loc=center1, size=num_examples)
# features for Class 1
f3 = normal(loc=center2, size=num_examples)
f4 = normal(loc=center2, size=num_examples)
# Adding features and corresponding class to the dataset
for i in range(num_examples):
dataset.append([f1[i], f2[i], 0])
dataset.append([f3[i], f4[i], 1])
# shuffling dataset to remove bias
random.shuffle(dataset)
return np.array(dataset)
myDataset = make_dataset(center1=0, center2=5, num_examples=50)
Here, arguments center1 and center2 are the centers of Class 0 and Class 1 respectively. num_examples determines the number of points in each class.
We then create our dataset myDataset with 0 and 5 as centers of classes with 50 points per class.
To get a clear idea about the classes, we plot them as follows:
import matplotlib.pyplot as plt
def plot_dataset(dataset):
# extracting features and classes (labels) from dataset
feature1 = dataset[:, 0]
feature2 = dataset[:, 1]
label = dataset[:, -1]
# adding the points as scatter plot with different colors
plt.scatter(feature1[label==0], feature2[label==0], c='r')
plt.scatter(feature1[label==1], feature2[label==1], c='b')
plt.legend(["Class 1", "Class 2"])
plt.show()
plot_dataset(myDataset)
We obtain the following plot:
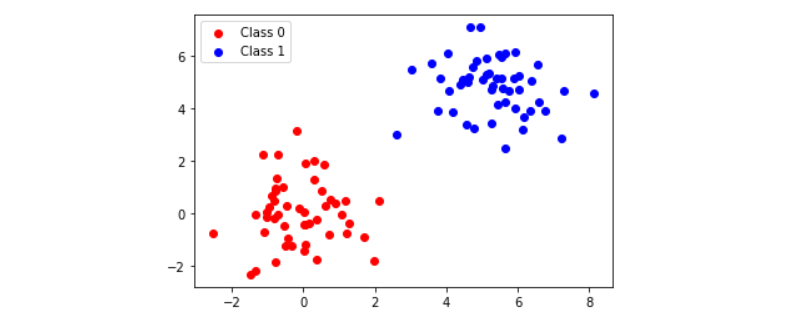
As we can see, we get two linearly separable classes in our dataset. Before going further, we also divide our dataset into training and testing splits.
from math import floor
def split_dataset(dataset, test_size):
# Calculating the point of split in the dataset
pivot = floor(len(dataset) * (1 - test_size))
# Labels are the last entries in dataset, remaining are features
X = [example[:-1] for example in dataset]
y = [example[-1] for example in dataset]
# Points before the pivot go to training set, rest to testing set
X_train = np.array(X[:pivot])
X_test = np.array(X[pivot:])
y_train = y[:pivot]
y_test = y[pivot:]
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = split_dataset(myDataset, test_size = 0.2)
Equipment
As we have mentioned earlier, Perceptron Algorithm is inspired by our Nervous System. A neuron receives inputs from other neurons, combines them and fires based on some threshold value. Similarly, a perceptron receives inputs (which are the features in our dataset), calculates a weighted sum and outputs 0 or 1 based on a threshold value.
To calculate the weighted sum, the perceptron has a set of weights where there is one weight per input feature. We also include a bias value which helps in adjusting the threshold at which the perceptron fires.
Thus, the output of a perceptron can be written as follow:
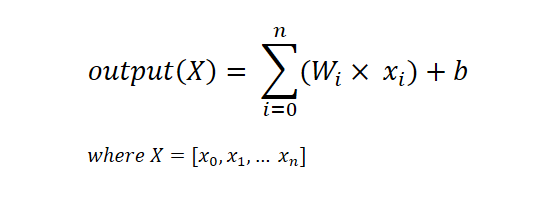
Here Wi denotes the weight for the feature Xi and b denotes the bias of the perceptron. This can be implemented as follows:
def weighted_sum(weights, bias, inputs):
summation = 0
for i in range(len(weights)):
summation += weights[i] * inputs[i]
return summation + bias
After combining the inputs, the perceptron outputs 0 or 1 based on the threshold function as shown below:
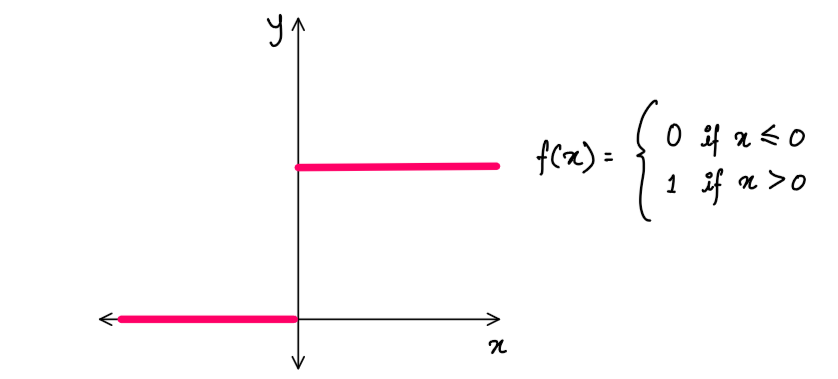
The threshold function has a very simple implementation.
def threshold(summation):
if summation > 0:
return 1
else:
return 0
Combining the weighted sum and threshold, we can now define the "activation" of perceptron as follows:
def activation(weights, bias, inputs):
# calculating weighted sum
weighted_sum = sum([weights[i] * inputs[i] for i in range(len(weights))])
weighted_sum += bias
# perceptron fires if weighted sum is above 0
return 1 if weighted_sum > 0 else 0
Directions
Contrary to popular belief, that imitating neurons lead to the success of the Perceptron algorithm, it was the update mechanism that made Perceptron such a breakthrough. As matter of fact, the "Perceptron Algorithm" is actually its update mechanism!
The update occurs the following way:
We initialize the weights and the bias for a perceptron. Weights are randomly initialized between 0 and 1, with their shape determined by the number of features in our dataset. Bias is usually set to zero.
We calculate the activation of perceptron for an input point and compare it to the point's actual label.
If the label matches the perceptron prediction, GREAT! We move on to the next point.
If the label doesn't match, we update the weights and bias as follows:

Steps 1-3 are repeated for each input point in the training dataset. And the entire process (called an epoch) is repeated multiple times until we achieve desired performance.
Here we come up with another new term "learning rate". It determines how much we want to update our weights and bias every time we incorrectly predict the label.
Selecting the proper value for the learning rate is an ability acquired only by Master Chefs! (Just kidding, some guidelines are discussed in the Further Reading section).
Directions can be encoded as follows:
def train(weights, bias, X, y, lr = 1, epochs = 100):
for _ in range(epochs):
for i in range(len(X)):
# Calculating activation for each training dataset example
example = X[i]
y_pred = activation(weights, bias, example)
# Updating the weights and bias using update rule
for j in range(len(weights)):
weights[j] += lr * (y[i] - y_pred) * example[j]
bias += lr * (y[i] - y_pred)
return weights, bias
# Shape of weights is determined by number of features.
# X_train has shape (num_training_examples, features)
weights = np.random.rand(X_train.shape[1])
bias = 0
# Training the perceptron
new_weights, new_bias = train(weights, bias, X_train, y_train)
# Calculating activation of each test point as prediction
predictions = [activation(new_weights, new_bias, X_test[i])
for i in range(len(X_test))]
Tasting 😋
It is time to check the savoriness, texture, aroma and taste of our Perceptron dish i.e., its accuracy!
We use the EXACT same strategy we used in the Simple KNN Recipe as follows:
def accuracy(actual, predicted):
correct = sum([1 for i in range(len(actual))
if actual[i]==predicted[i] ])
return correct/len(actual)
print(accuracy(y_test, predictions))
We obtain an accuracy score of ONE! i.e., 100%. That means we got all the points correctly classified. We can also visualize it by plotting the decision boundary using the weights and the bias for the perceptron.
def decision_boundary(dataset, weights, bias):
# Selecting range of X-coordinate
x = np.linspace(-4, 10, 100)
# Simplifying decision boundary equation for Y-coordinate
y = (-bias - weights[0] * x)/weights[1]
plt.plot(x, y)
# Plotting the points in dataset
f1, f2 = dataset[:, 0], dataset[:, 1]
label = dataset[:, -1]
plt.scatter(f1[label==0], f2[label==0], c='r')
plt.scatter(f1[label==1], f2[label==1], c='b')
plt.legend(["Decision Boundary", "Class 0", "Class 1"])
plt.show()
decision_boundary(myDataset, new_weights, new_bias)
We obtain the following graph:

Complete Code
Now that we have understood the inner workings of the Perceptron Algorithm, let us condense all the steps of the recipe into a single Perceptron class!
If you already knew the algorithm, this can be a handy recipe too!
import numpy as np
from numpy.random import normal
import random
import matplotlib.pyplot as plt
from math import floor
# ----- Defining the Perceptron Class ----- #
class Perceptron:
def __init__(self, num_features):
self.weights = np.random.rand(num_features)
self.bias = 0
def activation(self, inputs):
weighted_sum = sum([self.weights[i] * inputs[i]
for i in range(len(self.weights))])
return 1 if weighted_sum + self.bias > 0 else 0
def train(self, inputs, labels, lr = 1, epochs = 100):
for _ in range(epochs):
for i in range(len(inputs)):
example = inputs[i]
y_pred = self.activation(example)
for j in range(len(self.weights)):
self.weights[j] += lr * (labels[i] - y_pred) * example[j]
self.bias += lr * (labels[i] - y_pred)
# ----- Creating a dataset with two classes ----- #
def make_dataset(center1, center2, num_examples):
dataset = list()
f1 = normal(loc=center1, size=num_examples)
f2 = normal(loc=center1, size=num_examples)
f3 = normal(loc=center2, size=num_examples)
f4 = normal(loc=center2, size=num_examples)
for i in range(num_examples):
dataset.append([f1[i], f2[i], 0])
dataset.append([f3[i], f4[i], 1])
random.shuffle(dataset)
return np.array(dataset)
# ----- Preparing Training and Test Datasets ----- #
def split_dataset(dataset, test_size):
pivot = floor(len(dataset) * (1 - test_size))
X = [example[:-1] for example in dataset]
y = [example[-1] for example in dataset]
X_train, X_test = np.array(X[:pivot]), np.array(X[pivot:])
y_train, y_test = y[:pivot], y[pivot:]
return X_train, X_test, y_train, y_test
# ----- Plotting Dataset Points ----- #
def plot_dataset(dataset):
feature1 = dataset[:, 0]
feature2 = dataset[:, 1]
label = dataset[:, -1]
plt.scatter(feature1[label==0], feature2[label==0], c='r')
plt.scatter(feature1[label==1], feature2[label==1], c='b')
plt.legend(["Class 1", "Class 2"])
plt.show()
# ----- Plotting Decision boundary with Dataset points ----- #
def decision_boundary(dataset, weights, bias):
x = np.linspace(-2, 8, 100)
y = (-bias - weights[0] * x)/weights[1]
plt.plot(x, y)
f1, f2 = dataset[:, 0], dataset[:, 1]
label = dataset[:, -1]
plt.scatter(f1[label==0], f2[label==0], c='r')
plt.scatter(f1[label==1], f2[label==1], c='b')
plt.legend(["Decision Boundary", "Class 0", "Class 1"])
plt.show()
# ----- Calculating accuracy of the model ---- #
def accuracy(actual, predicted):
correct = sum([1 for i in range(len(actual))
if actual[i]==predicted[i]])
return correct/len(actual)
# --------------- MAIN PROGRAM EXECUTION --------------- #
# ----- Creating Dataset and training/testing splits -----#
myDataset = make_dataset(center1=0, center2=5, num_examples=50)
X_train, X_test, y_train, y_test = split_dataset(myDataset, test_size = 0.2)
# ----- Plotting points for visualization ----- #
plot_dataset(myDataset)
# ----- Using Perceptron Class to learn decision boundary ----- #
myPerceptron = Perceptron(num_features = X_train.shape[1])
myPerceptron.train(X_train, y_train, lr = 1, epochs = 100)
# ----- Calculating accuracy of our Perceptron ----- #
predictions = [myPerceptron.activation(X_test[i])
for i in range(len(X_test))]
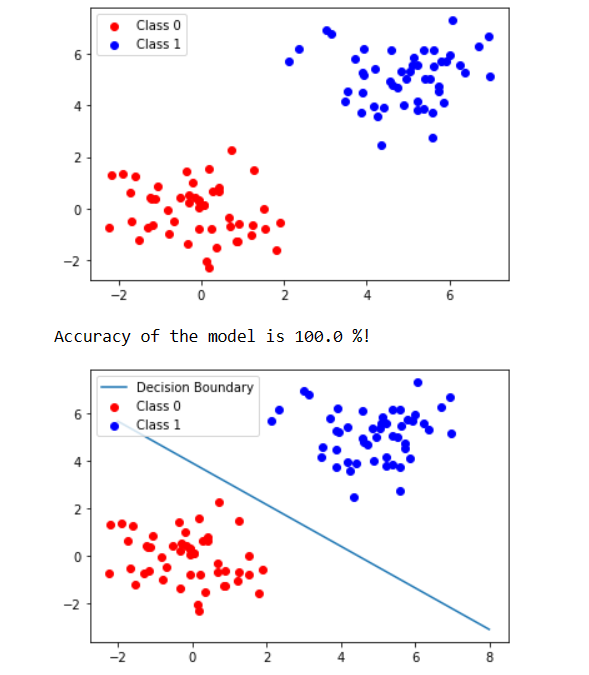
print(f"Accuracy of the model is {accuracy(y_test, predictions) * 100} %!")
# ----- Plotting the decision boundary ----- #
decision_boundary(myDataset, myPerceptron.weights, myPerceptron.bias)
We obtain the following output:
Further Reading
The hyperparameters we used - learning rate and epochs can be tweaked to achieve desired performance.
If the learning rate is too low, it can take very long for the algorithm to converge. On the flip side, if it is too high, the algorithm might not learn anything and the decision boundary will keep changing drastically for each data point.
Epochs are the number of times we wish to go through all the points in the training dataset for updating our perceptron.
If our dataset is linearly separable, the Perceptron Algorithm guarantees that it will converge in a finite number of steps i.e., the training error is zero.
It is also great for limited memory applications and works well with streaming data as we don't need to store anything and we can update the weights and the bias on the fly.
The ML-Cookbook repository contains the code for the above recipe as well as additional ML recipes (coming soon).
Hope this blog taught you a new ML recipe and improved you as a chef 👩🍳!




